
16강 | SQL에서는 반복을 어떻게 표현할까?
정리
- CASE 식과 윈도우 함수를 이용한다.
- 최대 반복 횟수가 정해진 경우 유용하게 사용할 수 있다.
- 반복 횟수가 정해지지 않은 경우
- 인접 리스트 모델과 재귀 쿼리를 사용한다.
- 중첩집합 모델을 이용하여 계층 구조를 표현한다.
예제문제 1
매출 계산을 하는 테이블이있을 때, 각 기업의 연도별 매출 변화를 나타내야한다.
var 필드를 추가하여 매출이 이전보다 올랐을 경우 +, 내렸을 경우 - , 동일한 경우 = 를 넣는다.
해당 문제는 15강에서 예시로 보였던 반복계 코드에 해당하는 문제이며, CASE식과 윈도우 함수를 이용하여 포장계 코드로 변경해야 한다.
- Sales 테이블

- 최종적으로 구해야할 Sales2 테이블
- 테이블 생성
-- Sales 테이블 생성
CREATE TABLE Sales (
company VARCHAR(50),
year INT,
sale INT
);
-- 데이터 입력
INSERT INTO Sales (company, year, sale) VALUES
('A', 2002, 50),
('A', 2003, 52),
('A', 2004, 55),
('B', 2001, 27),
('B', 2006, 28),
('B', 2009, 30),
('C', 2006, 40),
('C', 2010, 35);
-- Sales2 테이블 생성
CREATE TABLE Sales2 (
company VARCHAR(50),
year INT,
sale INT,
var VARCHAR(50)
);
- 반복계 코드
CREATE OR REPLACE PROCEDURE PROC_INSERT_VAR
IS
/* 커서 선언 */
CURSOR c_sales IS
SELECT company, year, sale
FROM Sales
ORDER BY company, year;
/* 레코드 타입 선언 */
rec_sales c_sales %ROWTYPE;
/* 카운터 */
i_pre_sale INTEGER :=0;
c_company CHAR(1) :='*';
c_var CHAR(1) :='*';
BEGIN
OPEN c_sales;
LOOP
/* 레코드를 패치해서 변수에 대입 */
fetch c_sales into rec_sales;
/* 레코드가 없다면 반복을 종료 */
exit when c_sales%notfound;
IF (c_company = rec_sales.company) THEN
/* 직전 레코드가 같은 회사의 레코드 일 때 */
/* 직전 레코드와 매상을 비교 */
IF (i_pre_sale < rec_sales.sale) THEN
c_var :='+';
ELSEIF(i_pre_sale > rec_sales.sale) THEN
c_var :='-';
ELSE
c_var :='=';
END IF;
ELSE
c_var :=NULL;
END IF;
/* 등록 대상이 테이블에 테이블을 등록 */
INSERT INTO Sales2 (company, year, sale, var)
VALUES (rec_sales.company, rec_sales.year, rec_sales.sale, c_var);
c_company := rec_sales.company;
i_pre_sale := rec_sales.sale;
END LOOP;
CLOSE c_sales;
commit;
END;
- 포장계 코드 (CASE와 윈도우 함수 사용)
- ROW BETWEEN 옵션
- 현재 레코드에서 N개의 이전부터 M개 이전까지의 레코드 범위를 가져온다.
- SIGN 함수
- 숫자 자료형을 매개변수로 받아 음수라면 -1 , 양수라면 1, 0이라면 0을 리턴한다.
- ROW BETWEEN 옵션
INSERT INTO Sales2
SELECT company,year,sale,
CASE SIGN(sale-MAX(sale) OVER(PARTITION BY company ORDER BY year ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING))
WHEN 0 THEN '='
WHEN 1 THEN '+'
WHEN -1 THEN '-'
ELSE NULL END AS var
FROM Sales;
- 결과
- 실행계획
SELECT 실행계획을 보면 풀스캔을 진행하고(type = ALL), 윈도우 함수를 정렬로 실행한다.
예제문제 2
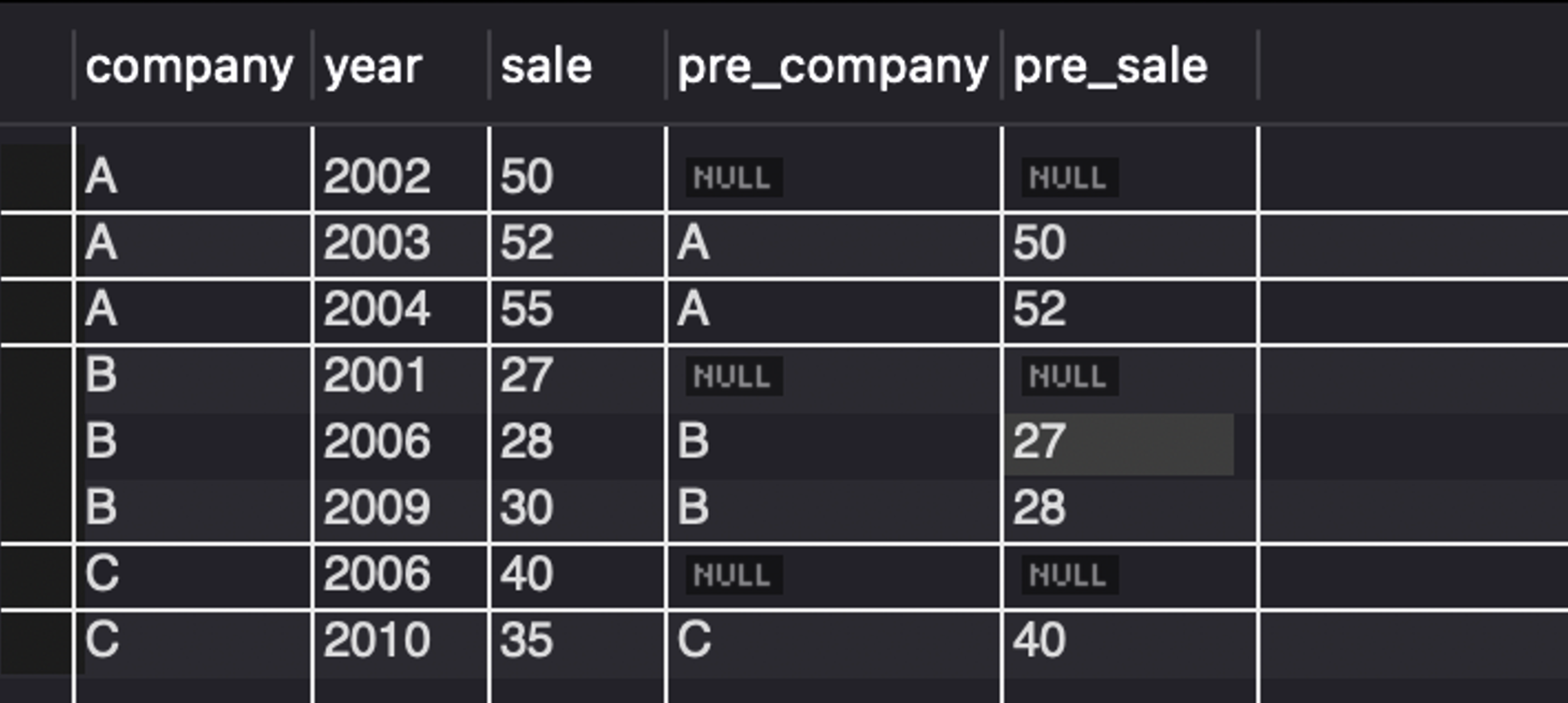
윈도우 함수로 Sales 테이블에서 ‘직전 회사명’과 ‘직전 매상’ 검색한다.
- 검색
- ROWS BETWEEN 을 이용하여 직전 행의 company와 sale 값을 가져왔다.
SELECT company,year,sale,
MAX(company) OVER (PARTITION BY company ORDER BY year ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS pre_company,
MAX(sale) OVER (PARTITION BY company ORDER BY year ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING ) AS pre_sale
FROM Sales;
- 결과
예제문제 3 (반복 횟수가 정해진 경우)
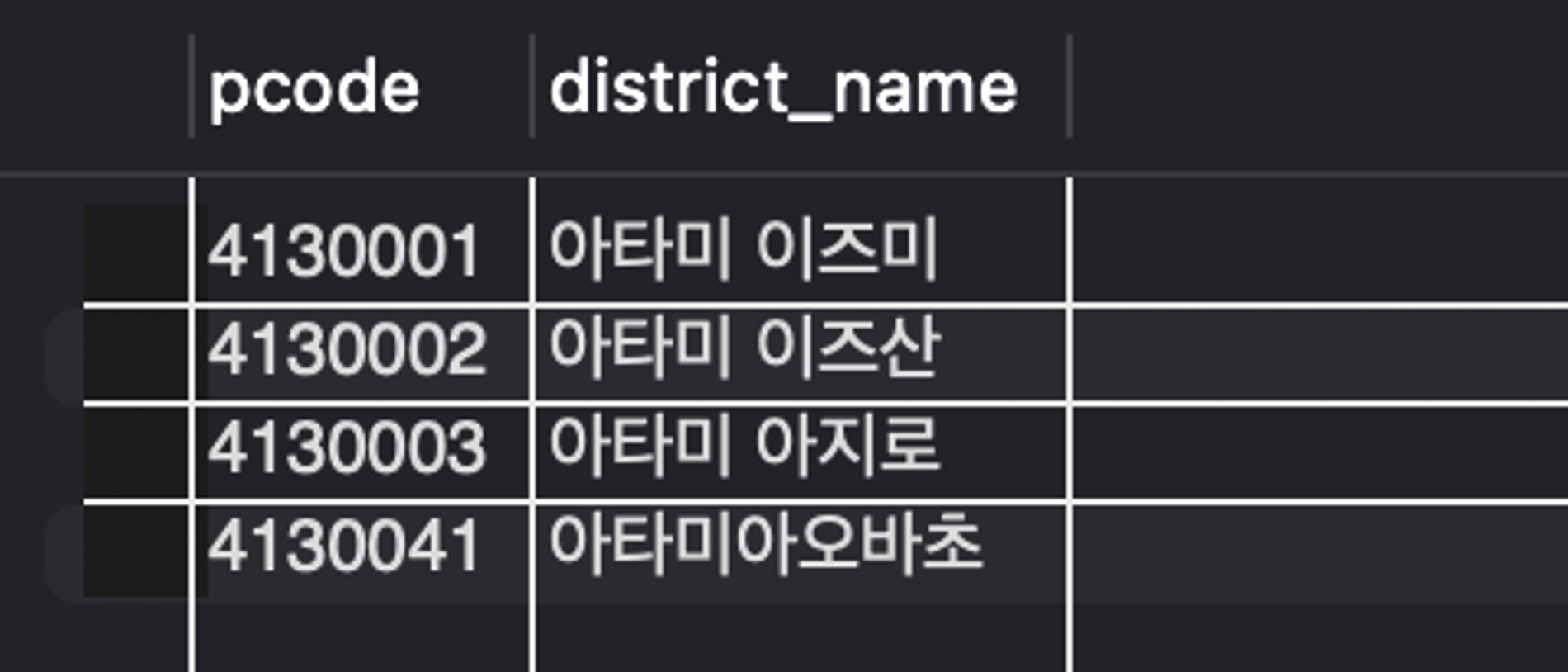
PostalCode 테이블에서 우편번호 4130033과 인접한 우편번호를 찾아야한다.
- PostalCode 테이블
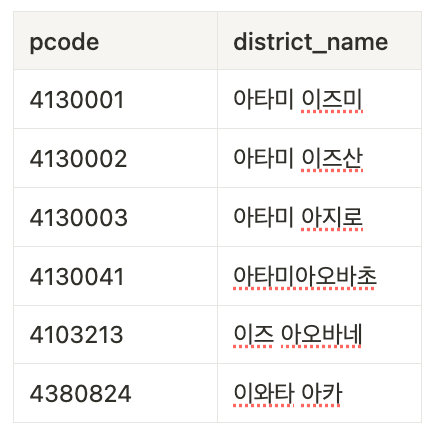
- 원하는 결과
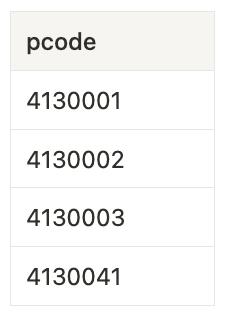
- 테이블 생성
-- PostalCode 테이블 생성
CREATE TABLE PostalCode (
pcode VARCHAR(10),
district_name VARCHAR(255)
);
-- 데이터 입력
INSERT INTO PostalCode (pcode, district_name) VALUES
('4130001', '아타미 이즈미'),
('4130002', '아타미 이즈산'),
('4130003', '아타미 아지로'),
('4130041', '아타미아오바초'),
('4103213', '이즈 아오바네'),
('4380824', '이와타 아카');
- 코드
우선 인접한 순서를 계산한다.
SELECT pcode,district_name,
CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END AS rank_value
FROM PostalCode;
- 순서 결과
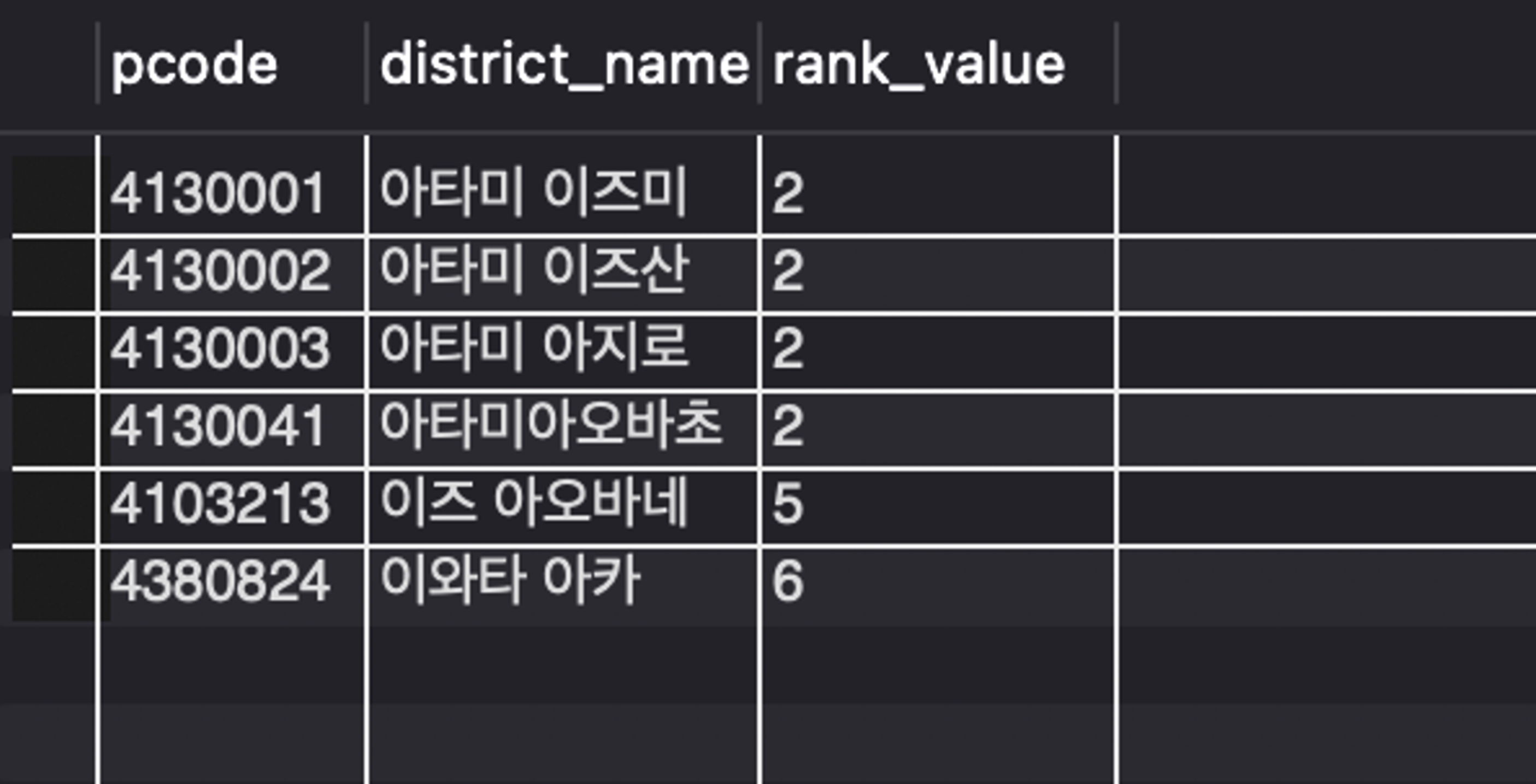
- MIN 함수를 이용하여 제일 인접한 우편번호를 구한다.
SELECT pcode,district_name
FROM PostalCode
where CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END = (SELECT MIN(
CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END)
FROM PostalCode );
- 결과
- 실행계획
서브쿼리로 인해 풀스캔이 2번 발생한다. 현재는 레코드 수가 몇개 안되어서 괜찮지만, 테이블 수가 수천만으로 늘어나면 시간이 꽤 걸릴 것이다. 따라서 스캔 횟수를 줄여야 한다.

- 윈도우 함수를 사용한 스캔 횟수 감소
두 번째 쿼리에서는 서브쿼리의 결과를 일시적인 테이블로 만들어두고, 그 테이블을 이용하여 메인 쿼리에서 필요한 데이터를 가져오기 때문에 풀 스캔이 한 번만 발생한다. MySQL 옵티마이저는 서브쿼리를 한 번만 실행하고 그 결과를 임시 테이블에 저장하며, 메인 쿼리에서는 해당 테이블을 사용하여 계산을 수행한다.
SELECT pcode,district_name
FROM (SELECT pcode,district_name,CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END AS hit_code,
MIN(
CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END
)
OVER(ORDER BY CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END) AS Min_code
FROM PostalCode
) Foo
WHERE hit_code = min_code;
예제문제 4 (반복 횟수가 정해지지 않은 경우)
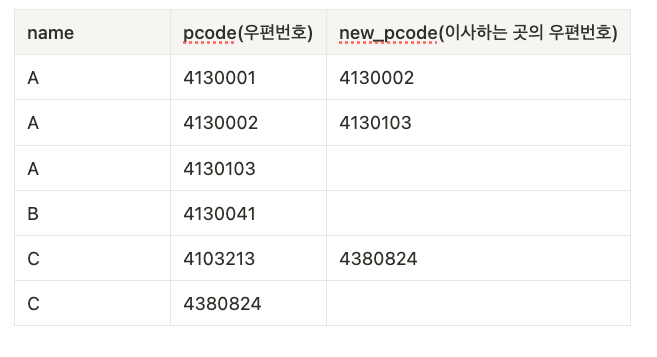
이번 문제는 예제문제3과 달리 현재주소뿐만 아니라 과거에 살던 주소까지 관리하는 테이블에서 가장 오래된 주소를 검색해야 한다. A가 가장 오래전에 살았던 주소를 검색해라
- PostalHistory 테이블
- 테이블 생성
-- PostalHistory 테이블 생성
CREATE TABLE PostalHistory (
name VARCHAR(255),
pcode INT,
new_pcode INT
);
-- 데이터 입력
INSERT INTO PostalHistory (name, pcode, new_pcode) VALUES
('A', 4130001, 4130002),
('A', 4130002, 4130103),
('A', 4130103, NULL),
('B', 4130041, NULL),
('C', 4103213, 4380824),
('C', 4380824, NULL);
- 인접 리스트 모델
- 한 가지 기준을 키로 삼아 데이터를 줄줄이 연결하는 것을 포인터 체인이라고 한다.
- A의 주소 변동 : 4130001 → 4130002 → 4130103
- 포인터 체인을 사용하는 PostalHistory 같은 테이블을 형식을 인접 리스트 모델이라 한다.
- 한 가지 기준을 키로 삼아 데이터를 줄줄이 연결하는 것을 포인터 체인이라고 한다.
- 재귀 검색
- 제일 최근에 이사한 주소(new_pcode = NULL)에서 거꾸로 예전 주소를 검색해 나간다.
- 최근 주소부터 탐색 : 4130103 → 4130002 → 4130001
- 재귀 공통 테이블 식 Explosion 생성
- 첫번째 SELECT 문 : 초기 셀프 조인으로, 시작 지점이다. PostalHistory 테이블에서 이름이 A이고 new_pcode가 없는 행을 찾는다.
- 두번째 SELECT 문 : Explosion 테이블과 PostalHistory 테이블을 조인하여 재귀 검색을 시작한다.
- Parent의 주소가 Child의 새로운 이사 주소인 행을 찾아 depth를 1 추가한다.
- 최종적으로 depth가 가장 큰 주소를 출력한다.
- 제일 최근에 이사한 주소(new_pcode = NULL)에서 거꾸로 예전 주소를 검색해 나간다.
-- 재귀 공통 테이블 식
WITH RECURSIVE Explosion(name,pcode,new_pcode,depth)
AS(
SELECT name,pcode,new_pcode,1
FROM PostalHistory
WHERE name ='A'
AND new_pcode IS NULL
UNION
SELECT Child.name,Child.pcode,Child.new_pcode,depth +1
FROM Explosion AS Parent,PostalHistory AS Child
WHERE Parent.pcode = Child.new_pcode AND Parent.name = Child.name
)
SELECT name,pcode,new_pcode
FROM Explosion
WHERE depth = (SELECT MAX(depth) FROM Explosion);
- 결과
- 재귀 검색은 반복 횟수 제한 없이 원하는 결과값을 찾을 수 있다는 것에서 굉장히 유연하다.
'BOOK > SQL 레벨업' 카테고리의 다른 글
| [SQL 레벨업] 19강 결합 알고리즘과 성능 (1) | 2024.02.05 |
|---|---|
| [SQL 레벨업] 18강 기능적 관점으로 구분하는 결합의 종류 (1) | 2024.01.30 |
| [SQL 레벨업] 15강 반복계의 공포 (1) | 2024.01.25 |
| [SQL 레벨업] 13강 자르기 (1) | 2024.01.23 |
| [SQL 레벨업] 12강 집약 (0) | 2024.01.10 |