19강 | 결합 알고리즘과 성능
정리
옵티마이저가 선택 가능한 결합 알고리즘 (데이터의 크기 또는 결합 키의 분산으로 결정)
- Nested Loops
- Hash
- Sort Merge
Nested Loops 알고리즘
- 각종 결합 알고리즘의 기본이 되는 알고리즘
- 중첩 반복을 사용하는 알고리즘
- 세부 처리
- 외부 테이블(TableA)에서 레코드를 하나씩 반복하며 스캔
- 외부 테이블 레코드 하나마다 내부테이블(TableB)의 레코드를 하나씩 스캔에서 결합조건에 맞으면 리턴
- 위의 과정을 외부 테이블 모든 레코드에 반복

- 특징
- 각 테이블의 결합 대상 레코드 수가 R(A) ,R(B) 일때 접근되는 레코드 수는 R(A) X R(B)가 된다.
- 실행시간은 레코드 수에 비례
- 한번의 단계에서 처리하는 레코드 수가 적으므로 Hash 또는 Sort Merge에 비해 메모리 소비가 적다.
- 모든 DBMS 지원
- 성능 개선
- 내부 테이블 결합 키 필드에 인덱스가 존재할때, 구동 테이블로는 작은 테이블을 선택하는 것이 성능 개선에 도움이 된다.
- 실행계획
// 내부 테이블(D)를 PK로 인덱스를 조회
EXPLAIN SELECT E.emp_id,E.emp_name,E.dept_id,D.dept_name
FROM Employees E INNER JOIN Department D
ON D.dept_id = E.dept_id;

- 성능 저하 경우
- 내부 테이블의 선택률이 높으면 성능이 악화
- 결합 키로 내부 테이블에 유일하지 않거나 양이 너무 많아, 접근할 때 히트되는 레코드가 많기 때문
- 내부 테이블의 선택률이 높으면 성능이 악화
Hash 알고리즘
- 해시 결합 과정
- 작은 테이블을 스캔해서 결합 키에 해시 함수를 적용하여 해시 값으로 변환한다.
- (해시 테이블은 DBMS의 워킹 메모리에 저장되므로 조금이라도 작은 것이 효율적이다.)
- 다른 테이블(큰 테이블)을 스캔하고, 결합 키가 해시 값에 존재하는지 확인
- 작은 테이블을 스캔해서 결합 키에 해시 함수를 적용하여 해시 값으로 변환한다.

- 특징
- 결합 테이블로부터 해시 테이블을 만들어서 활용하므로 Nested Loops에 비해 메모리를 크게 소모한다.
- 메모리가 부족하면 저장소를 사용하므로 지연이 발생한다.
- 출력되는 해시값은 입력값의 순서를 알지 못하므로, 등치 결합에만 사용할 수 있다.
- 유용한 경우
- Nested Loops에서 적절한 구동테이블이 존재하지 않는 경우(상대적으로 충분히 작은 테이블이 존재하지 않는 경우)
- Nested Loops에서 적절한 구동 테이블이 존재하지만, 내부 테이블에서 히트되는 레코드 수가 많은 경우
- Nested Loops의 내부 테이블에 인덱스가 존재하지 않는 경우
- ⇒ Nested Loops가 효율적으로 작동하지 않는 경우의 차선책
- 주의해야할 트레이드오프
- 해시 테이블 생성으로 인해, Nested Loops에 비해 소비하는 메모리 양이 많다.
- 동시 실행성이 높은 OLTP 처리를 할 때 Hash 사용으로 메모리가 부족해져 저장소 사용 → 지연 발생 리스크
- 동시 처리가 적은 야간 배치와 같은 시스템에 한해 사용하는 것이 hash 사용 기본 전략
- 해시 결합은 양쪽 테이블의 레코드를 반드시 전부 읽어야 하므로, 테이블 풀 스캔이 적용되는 경우가 많다
- 테이블의 규모가 크다면 풀 스캔에 걸리는 시간도 고려해야 한다.
- 해시 테이블 생성으로 인해, Nested Loops에 비해 소비하는 메모리 양이 많다.
Sort 알고리즘
- Sort Merge 과정
- 결합 대상 테이블들을 각각 결합 키로 정렬하고, 일치하는 결합 키를 찾으면 결합한다.

- 특징
- 메모리 부족
- 대상 테이블을 모두 정렬해야함 → Nested Loops 보다 많은 메모리 소비
- Hash는 한쪽 테이블에 대해서만 해시 테이블을 만든다 → hash보다 많은 메모리 사용
- 메모리 부족으로 TEMP 탈락이 발생하면 I/O 비용이 늘어나고 지연 발생 위험
- 동치결합뿐만 아니라 부등호를 사용한 결합에도 사용할 수 있다.
- 부정 조건 결합에서는 사용할 수 없음
- 테이블이 결합 키로 정렬되어 있다면 정렬을 생략할 수 있다.
- SQL에서 테이블에 있는 레코드의 물리적인 위치를 알고 있을 때만 가능
- 테이블을 정렬하므로 한쪽 테이블을 모두 스캔한 시점에 결합을 완료할 수 있다.
- 메모리 부족
- 유효한 경우
- 테이블 정렬에 많은 시간과 리소스를 요구할 가능성이 있다.
- 따라서 테이블 정렬을 생략할 수 있는 경우에만 고려, 그 외에는 Nested Loops와 hash를 우선적으로 고려할 것
- 테이블 정렬에 많은 시간과 리소스를 요구할 가능성이 있다.
의도하지 않은 크로스 결합
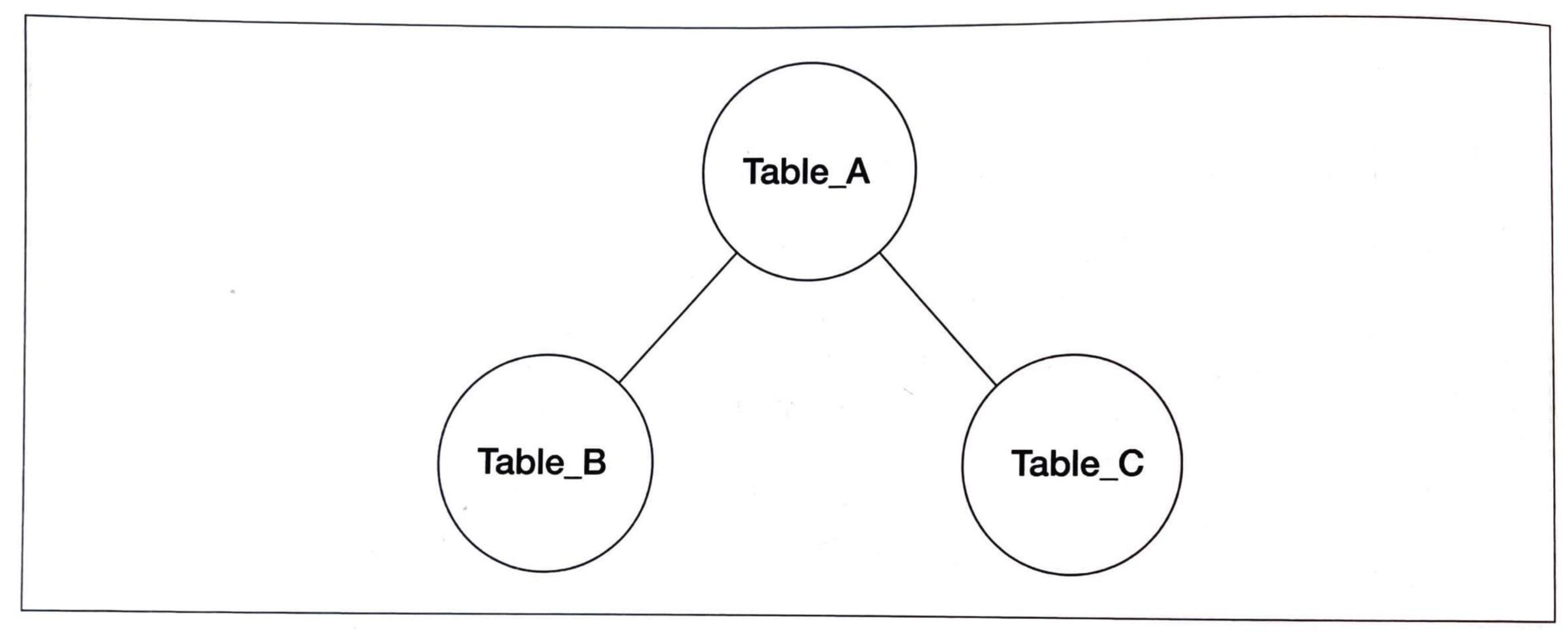
- 크로스 결합이 선택되는 경우
- 3개 이상의 테이블을 사용할 때, 두개의 테이블 결합에 조건이 없는 경우 크로스 결합으로 결합한다.
- 비효율적인 크로스 결합이 선택되는 이유는, Table B와 C가 크기가 작다고 평가했을 가능성이 있다.(테이블이 큰 A를 두번 결합하는 것보단 작은 테이블들을 먼저 결합하고 다시 결합하는 것이 합리적이라 판단)
//table B와 C에 대한 결합 조건이 존재하지 않는다.
SELECT a.col_a,B.col_b,C.col_c
FROM Table_A A
INNER JOIN Table_B B ON A.col_a = B.col_b
INNER JOIN Table_C C ON A.col_a = C.col_c;
- 크로스 결합 회피하는 방법
- 불필요한 결합 조건을 추가
//table B와 C에 대한 결합 조건이 존재하지 않는다.
SELECT a.col_a,B.col_b,C.col_c
FROM Table_A A
INNER JOIN Table_B B ON A.col_a = B.col_b
INNER JOIN Table_C C ON A.col_a = C.col_c AND C.col_c = B.col_b;
'BOOK > SQL 레벨업' 카테고리의 다른 글
| [SQL 레벨업] 20강. 결합이 느리다면 (0) | 2024.02.06 |
|---|---|
| [SQL 레벨업] 18강 기능적 관점으로 구분하는 결합의 종류 (1) | 2024.01.30 |
| [SQL 레벨업] 16강 SQL에서는 반복을 어떻게 표현할까? (1) | 2024.01.27 |
| [SQL 레벨업] 15강 반복계의 공포 (1) | 2024.01.25 |
| [SQL 레벨업] 13강 자르기 (1) | 2024.01.23 |